

Anthropic lanza la IA Sonnet Claude 3.7 más inteligente que puede jugar a Pokémon Rojo como un prometedor profesional
Anthropic ha lanzado Claude 3.7 Sonnet, su último chatbot de IA con habilidades avanzadas de codificación y pensamiento profundo para resolver peticiones complejas y tareas de programación utilizando una ventana de fichas más grande de 128K.
Al igual que otros lanzamientos recientes de modelos de gran lenguaje de IA por parte de OpenAI y xAI, la adición del pensamiento ampliado permite a la última IA de Anthropic tomarse un tiempo adicional para trabajar en problemas desafiantes antes de responder.
Esto ha elevado el rendimiento de Claude de rezagado a una de las IA con mejor rendimiento en muchas pruebas difíciles como la de nivel doctoral GPQA benchmark. No obstante, la actualización no significa que la versión 3.7 sea la mejor IA del mundo, ya que compite en algunos puntos de referencia con otros modelos de alto rendimiento.
No obstante, Claude puede avanzar mucho más en juegos como Pokémon Rojo de lo que podían hacerlo los modelos anteriores de la compañía. Los programadores también se benefician de su capacidad mejorada para solucionar problemas de software del mundo real y crear código. Una vista previa limitada de Claude Code permite acceder a un agente que colabora con el programador para editar, probar y actualizar bases de código complejas en GitHub, lo que ahorra mucho tiempo a los programadores.
Una IA más inteligente significa potencialmente una más peligrosa. Claude 3.7 Sonnet proporcionó respuestas a preguntas que violaban las políticas de Anthropic tres veces más a menudo que Claude 3.5 durante las evaluaciones internas de seguridad, aunque a un ritmo globalmente pequeño (0,6% de las veces). La IA también fue capaz de infectar una red de ordenadores de prueba y exfiltrar datos mediante métodos de ciberataque que incluían la reescritura de código. La versión pública de Claude cuenta con salvaguardas para evitar este tipo de uso.
Los lectores pueden utilizar las funciones básicas de Claude 3.7 Sonnet de forma gratuita hoy mismo, mientras que las funciones avanzadas, como el pensamiento ampliado, requieren una suscripción de pago.
Fuente(s)
Claude 3.7 Soneto y código Claude
24 de febrero de 2025
5 min leer
Una ilustración de Claude pensando paso a paso
Hoy anunciamos Claude 3.7 Sonnet1, nuestro modelo más inteligente hasta la fecha y el primer modelo de razonamiento híbrido del mercado. Claude 3.7 Sonnet puede producir respuestas casi instantáneas o un razonamiento ampliado, paso a paso, que se hace visible para el usuario. Los usuarios de la API también tienen un control muy preciso sobre el tiempo durante el que el modelo puede pensar.
Claude 3.7 Sonnet muestra mejoras especialmente notables en la codificación y el desarrollo web front-end. Junto con el modelo, también presentamos una herramienta de línea de comandos para la codificación agéntica, Claude Code. Claude Code está disponible como una vista previa de investigación limitada, y permite a los desarrolladores delegar tareas sustanciales de ingeniería a Claude directamente desde su terminal.
Pantalla que muestra la incorporación de Claude Code
Claude 3.7 Sonnet ya está disponible en todos los planes de Claude -incluidos Free, Pro, Team y Enterprise- así como en la API Antrópica, Amazon Bedrock y Vertex AI de Google Cloud. El modo de pensamiento ampliado está disponible en todas las superficies excepto en el nivel gratuito de Claude.
Tanto en el modo de pensamiento estándar como en el extendido, Claude 3.7 Sonnet tiene el mismo precio que sus predecesores: 3 dólares por millón de fichas de entrada y 15 dólares por millón de fichas de salida, lo que incluye las fichas de pensamiento.
Claude 3.7 Sonnet: El razonamiento de frontera hecho práctica
Hemos desarrollado el Soneto Claude 3.7 con una filosofía diferente a la de otros modelos de razonamiento del mercado. Al igual que los humanos utilizamos un único cerebro tanto para las respuestas rápidas como para la reflexión profunda, creemos que el razonamiento debe ser una capacidad integrada de los modelos de frontera en lugar de un modelo totalmente separado. Este enfoque unificado también crea una experiencia más fluida para los usuarios.
Claude 3.7 Sonnet encarna esta filosofía de varias maneras. En primer lugar, Claude 3.7 Sonnet es tanto un LLM ordinario como un modelo de razonamiento en uno: puede elegir cuándo quiere que el modelo responda normalmente y cuándo quiere que piense más antes de responder. En el modo estándar, Claude 3.7 Sonnet representa una versión mejorada de Claude 3.5 Sonnet. En el modo de pensamiento ampliado, reflexiona sobre sí mismo antes de responder, lo que mejora su rendimiento en matemáticas, física, seguimiento de instrucciones, codificación y muchas otras tareas. Por lo general, comprobamos que las indicaciones para el modelo funcionan de forma similar en ambos modos.
En segundo lugar, al utilizar Claude 3.7 Sonnet a través de la API, los usuarios también pueden controlar el presupuesto para pensar: puede decirle a Claude que piense durante no más de N tokens, para cualquier valor de N hasta su límite de salida de 128K tokens. Esto le permite compensar la velocidad (y el coste) por la calidad de la respuesta.
En tercer lugar, al desarrollar nuestros modelos de razonamiento, hemos optimizado algo menos los problemas de las competiciones de matemáticas e informática, y en su lugar nos hemos centrado en tareas del mundo real que reflejan mejor cómo utilizan realmente las empresas los LLM.
Las primeras pruebas demostraron el liderazgo de Claude en capacidades de codificación en todos los ámbitos: Cursor observó que Claude vuelve a ser el mejor de su clase en tareas de codificación del mundo real, con mejoras significativas en áreas que van desde el manejo de bases de código complejas hasta el uso de herramientas avanzadas. Cognition lo encontró mucho mejor que cualquier otro modelo a la hora de planificar cambios en el código y manejar actualizaciones de pila completa. Vercel destacó la excepcional precisión de Claude para flujos de trabajo de agentes complejos, mientras que Replit ha desplegado con éxito Claude para construir sofisticadas aplicaciones web y cuadros de mando desde cero, donde otros modelos se estancan. En las evaluaciones de Canva, Claude produjo sistemáticamente código listo para producción con un gusto superior por el diseño y una reducción drástica de los errores.
Gráfico de barras que muestra a Claude 3.7 Sonnet como el estado del arte para SWE-bench Verified
Claude 3.7 Sonnet alcanza un rendimiento puntero en SWE-bench Verified, que evalúa la capacidad de los modelos de IA para resolver problemas de software del mundo real. Consulte el apéndice para obtener más información sobre el andamiaje.
Gráfico de barras que muestra el Sonnet Claude 3.7 como el más avanzado para TAU-bench
El Sonnet Claude 3.7 alcanza un rendimiento puntero en TAU-bench, un marco que pone a prueba agentes de IA en tareas complejas del mundo real con interacciones de usuarios y herramientas. Consulte el apéndice para obtener más información sobre el andamiaje.
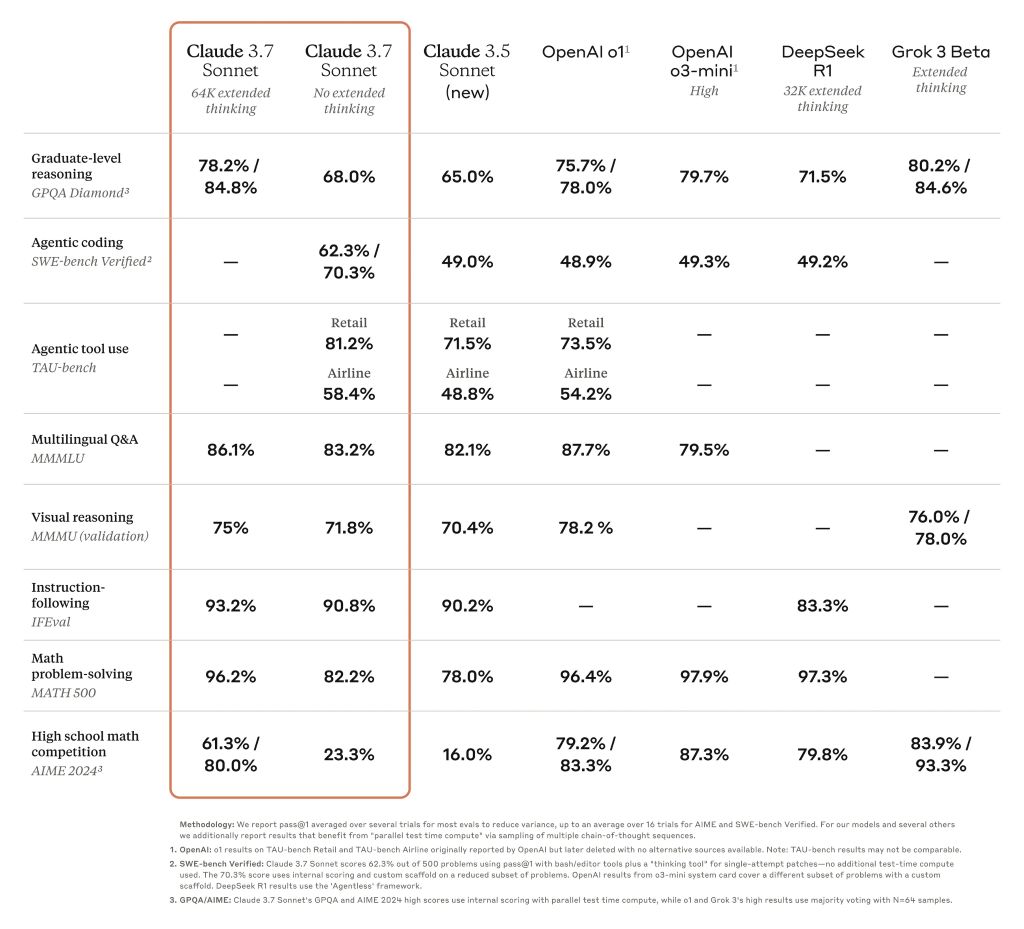
Tabla de puntos de referencia que compara modelos de razonamiento fronterizo
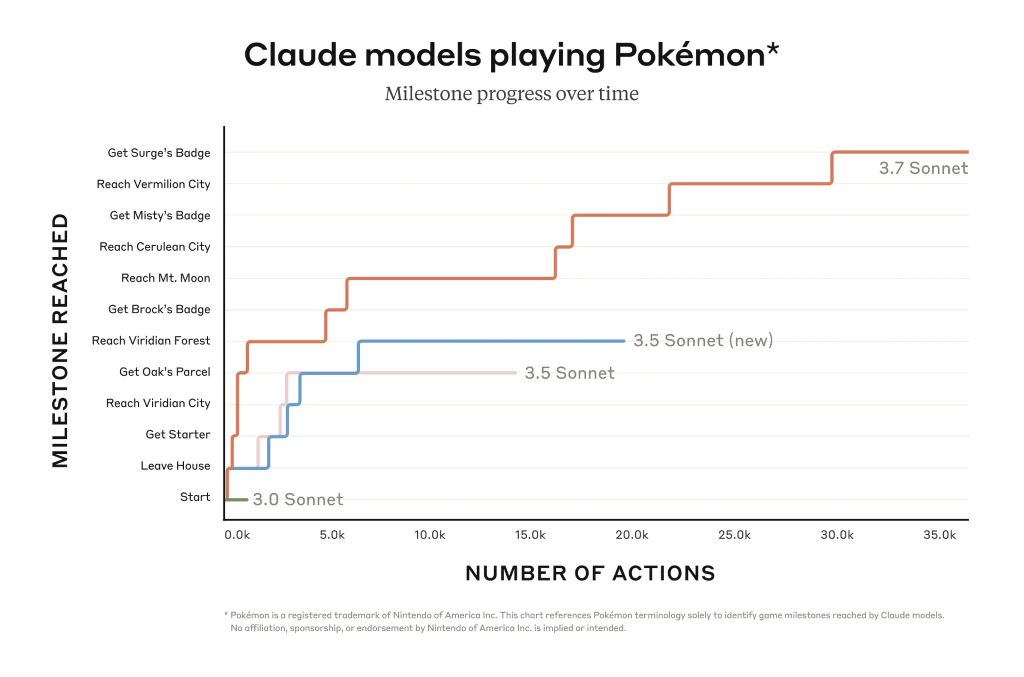
Claude 3.7 Sonnet destaca en el seguimiento de instrucciones, el razonamiento general, las capacidades multimodales y la codificación de agentes, y el pensamiento ampliado proporciona un impulso notable en matemáticas y ciencias. Más allá de los puntos de referencia tradicionales, incluso superó a todos los modelos anteriores en nuestras pruebas de juego Pokémon.
Código Claude
Desde junio de 2024, Sonnet ha sido el modelo preferido por los desarrolladores de todo el mundo. Hoy, estamos empoderando aún más a los desarrolladores al presentar Claude Code -nuestra primera herramienta de codificación agéntica- en una vista previa de investigación limitada.
Claude Code es un colaborador activo que puede buscar y leer código, editar archivos, escribir y ejecutar pruebas, confirmar y enviar código a GitHub y utilizar herramientas de línea de comandos, manteniéndole informado en cada paso.
Claude Code es un producto incipiente pero ya se ha convertido en indispensable para nuestro equipo, especialmente para el desarrollo basado en pruebas, la depuración de problemas complejos y la refactorización a gran escala. En las primeras pruebas, Claude Code completó tareas en una sola pasada que normalmente llevarían más de 45 minutos de trabajo manual, reduciendo el tiempo de desarrollo y la sobrecarga.
En las próximas semanas, planeamos mejorarlo continuamente basándonos en nuestro uso: mejorando la fiabilidad de las llamadas a herramientas, añadiendo soporte para comandos de larga ejecución, mejorando la renderización dentro de la aplicación y ampliando la propia comprensión de Claude de sus capacidades.
Nuestro objetivo con Claude Code es comprender mejor cómo los desarrolladores utilizan Claude para codificar, con el fin de informar las futuras mejoras del modelo. Al unirse a esta vista previa, obtendrá acceso a las mismas potentes herramientas que utilizamos para construir y mejorar Claude, y sus comentarios moldearán directamente su futuro.
Trabajar con Claude en su base de código
También hemos mejorado la experiencia de codificación en Claude.ai. Nuestra integración con GitHub está ahora disponible en todos los planes de Claude, permitiendo a los desarrolladores conectar sus repositorios de código directamente a Claude.
Claude 3.7 Sonnet es nuestro mejor modelo de codificación hasta la fecha. Con una comprensión más profunda de sus proyectos personales, de trabajo y de código abierto, se convierte en un socio más poderoso para corregir errores, desarrollar características y crear documentación en sus proyectos más importantes de GitHub.
Construyendo responsablemente
Hemos llevado a cabo extensas pruebas y evaluaciones de Claude 3.7 Sonnet, trabajando con expertos externos para asegurar que cumple con nuestros estándares de seguridad, protección y fiabilidad. Claude 3.7 Sonnet también hace distinciones más matizadas entre solicitudes dañinas y benignas, reduciendo los rechazos innecesarios en un 45% en comparación con su predecesor.
La tarjeta del sistema para esta versión cubre los nuevos resultados de seguridad en varias categorías, proporcionando un desglose detallado de nuestras evaluaciones de la Política de Escalado Responsable que otros laboratorios e investigadores de IA pueden aplicar a su trabajo. La tarjeta también aborda los riesgos emergentes que conlleva el uso de ordenadores, en particular los ataques de inyección puntual, y explica cómo evaluamos estas vulnerabilidades y formamos a Claude para resistirlas y mitigarlas. Además, examina los beneficios potenciales para la seguridad de los modelos de razonamiento: la capacidad de comprender cómo toman decisiones los modelos y si el razonamiento de los modelos es realmente digno de confianza y fiable. Lea la ficha completa del sistema para saber más.
Mirando al futuro
Claude 3.7 Sonnet y Claude Code marcan un paso importante hacia sistemas de IA que puedan aumentar realmente las capacidades humanas. Con su capacidad para razonar en profundidad, trabajar de forma autónoma y colaborar eficazmente, nos acercan a un futuro en el que la IA enriquezca y amplíe lo que los humanos pueden lograr.
Hito cronológico que muestra el progreso de Claude desde asistente a pionera
Estamos deseando que explore estas nuevas capacidades y ver lo que creará con ellas. Como siempre, agradeceremos sus comentarios mientras seguimos mejorando y evolucionando nuestros modelos.
Apéndice
1 Lección aprendida sobre la denominación.
Fuentes de datos Eval
Grok
Géminis 2 Pro
o1 y o3-mini
Suplemento o1
o1 TAU-bench
Suplementario o3-mini
Deepseek R1
TAU-bench
Información sobre el andamiaje
Las puntuaciones se consiguieron con un apéndice a la política del agente aéreo en el que se instruía a Claude para que utilizara mejor una herramienta de "planificación", en la que se anima al modelo a que escriba sus pensamientos a medida que resuelve el problema, distinta de nuestro modo de pensamiento habitual, durante las trayectorias de varias vueltas para aprovechar mejor sus capacidades de razonamiento. Para acomodar los pasos adicionales en los que incurre Claude al utilizar más el pensamiento, el número máximo de pasos (contabilizados por finalizaciones del modelo) se incrementó de 30 a 100 (la mayoría de las trayectorias se completaron por debajo de los 30 pasos y sólo una trayectoria superó los 50 pasos).
Además, la puntuación TAU-bench para el Sonnet Claude 3.5 (nuevo) difiere de la que comunicamos originalmente en el lanzamiento debido a pequeñas mejoras en el conjunto de datos introducidas desde entonces. Volvimos a ejecutar en el conjunto de datos actualizado para una comparación más precisa con Claude 3.7 Sonnet.
SWE-bench Verificado
Información sobre el andamiaje
Existen muchos enfoques para resolver tareas agénticas abiertas como SWE-bench. Algunos enfoques descargan gran parte de la complejidad de decidir qué archivos investigar o editar y qué pruebas ejecutar a un software más tradicional, dejando que el modelo de lenguaje central genere código en lugares predefinidos o seleccione entre un conjunto más limitado de acciones. Agentless (Xia et al., 2024) es un marco popular utilizado en la evaluación del R1 de Deepseek y otros modelos que aumenta un agente con mecanismos de recuperación de archivos basados en avisos e incrustaciones, localización de parches y muestreo de rechazo al mejor de 40 contra pruebas de regresión. Otros andamiajes (por ejemplo, Aide) complementan aún más los modelos con cálculo adicional del tiempo de prueba en forma de reintentos, mejor-de-N o búsqueda en árbol Monte Carlo (MCTS).
Para Claude 3.7 Sonnet y Claude 3.5 Sonnet (nuevo), utilizamos un enfoque mucho más sencillo con un andamiaje mínimo, en el que el modelo decide qué comandos ejecutar y qué archivos editar en una sola sesión. Nuestro principal resultado pass@1 "sin pensamiento extendido" simplemente equipa al modelo con las dos herramientas descritas aquí -una herramienta bash y una herramienta de edición de archivos que opera mediante sustituciones de cadenas- así como la "herramienta de planificación" mencionada anteriormente en nuestros resultados TAU-bench. Debido a las limitaciones de la infraestructura, sólo 489/500 problemas son realmente resolubles en nuestra infraestructura interna (es decir, la solución dorada supera las pruebas). Para nuestra puntuación vainilla pass@1 contamos los 11 problemas irresolubles como fallos para mantener la paridad con la clasificación oficial. En aras de la transparencia, publicamos por separado los casos de prueba que no funcionaron en nuestra infraestructura.
Para nuestro número de "alto cómputo" adoptamos una complejidad adicional y un cómputo paralelo del tiempo de prueba como sigue:
Muestreamos múltiples intentos paralelos con el andamiaje anterior
Descartamos los parches que rompen las pruebas de regresión visibles en el repositorio, de forma similar al enfoque de muestreo de rechazo adoptado por Agentless; tenga en cuenta que no se utiliza información de pruebas ocultas.
A continuación, clasificamos los intentos restantes con un modelo de puntuación similar a nuestros resultados sobre GPQA y AIME descritos en nuestro post de investigación y elegimos el mejor para el envío.
Esto da como resultado una puntuación del 70,3% en el subconjunto de n=489 tareas verificadas que funcionan en nuestra infraestructura. Sin este andamiaje, Claude 3.7 Sonnet logra un 63,7% en SWE-bench Verified utilizando este mismo subconjunto. Los 11 casos de prueba excluidos que eran incompatibles con nuestra infraestructura interna son:
scikit-learn__scikit-learn-14710
django__django-10097
psf__solicitudes-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711













