

Las comunicaciones internas filtradas revelan que Nvidia rastrea diariamente toda una vida de vídeos de YouTube para entrenar el modelo de IA de vídeo, Jensen está satisfecho con el progreso

Nvidia está entrenando sus Omniversos, coches autoconducidos y coches "humanos digitales" basándose en datos extraídos de "80 años de vídeos al día" de YouTube y otras fuentes, según reveló una investigación de 404 Media.
Las comunicaciones internas filtradas obtenidas por 404 Media indican que Nvidia está utilizando estos datos para entrenar su modelo de IA del mundo del vídeo apodado Cosmos (que no debe confundirse con el servicio de aprendizaje profundo Cosmos ya existente de la empresa https://www.nvidia.com/es-la/gpu-cloud/deep-learning-software/?ref=404media.co). Cosmos está pensado internamente como un modelo que impulsaría otras líneas de Nvidia, como GeForce, la arquitectura de GPU, DGX, los marcos de aprendizaje profundo, Omniverse, Avatar, el Proyecto GR00T y los vehículos autónomos.
Los ejecutivos de Nvidia apodaron a Cosmos como un modelo base de última generación"que encapsula la simulación del transporte de la luz, la física y la inteligencia en un solo lugar para desbloquear varias aplicaciones posteriores críticas para Nvidia"
404 Media accedió a mensajes internos de Slack de empleados que revelaban cómo el personal utilizaba el programa de línea de comandos yt-dlp para descargar vídeos de YouTube utilizando entre 20 y 30 máquinas virtuales de AWS que refrescaban las direcciones IP para evitar ser bloqueadas por YouTube. El sitio para compartir vídeos fue la fuente principal para el scraping de vídeos, aunque los empleados también barajaron otras fuentes como Netflix y Discovery Channel.
Las comunicaciones de Slack muestran a los empleados discutiendo las ramificaciones legales del scraping de contenido con derechos de autor para entrenar la IA, sólo para ser descartado por los jefes de proyecto como una decisión ejecutiva, y eso es algo de lo que no deben preocuparse.
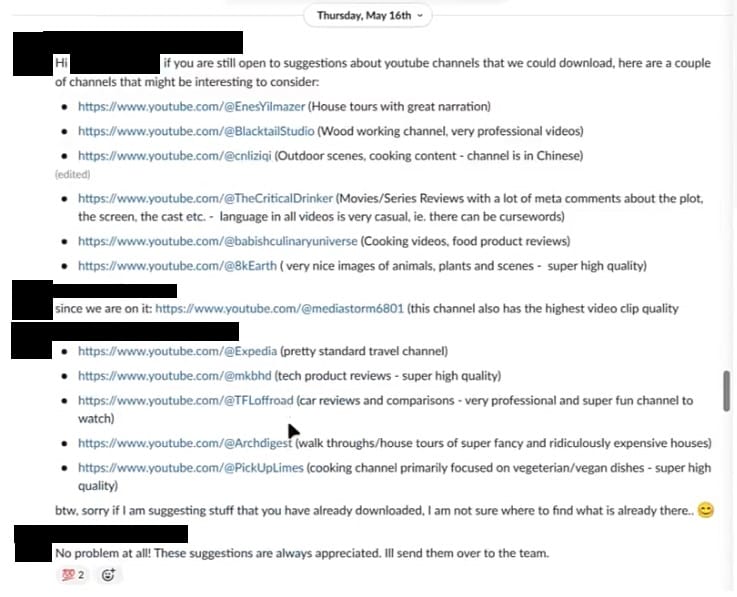
Entre los canales populares de YouTube que los empleados de Nvidia han preseleccionado se encuentran MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth y The CriticalDrinker, entre otros.
Cuando 404 Media se puso en contacto con ellos, tanto YouTube como Netflix dijeron que el raspado de contenidos en sus plataformas para entrenar modelos de IA es una clara violación de sus condiciones de servicio.
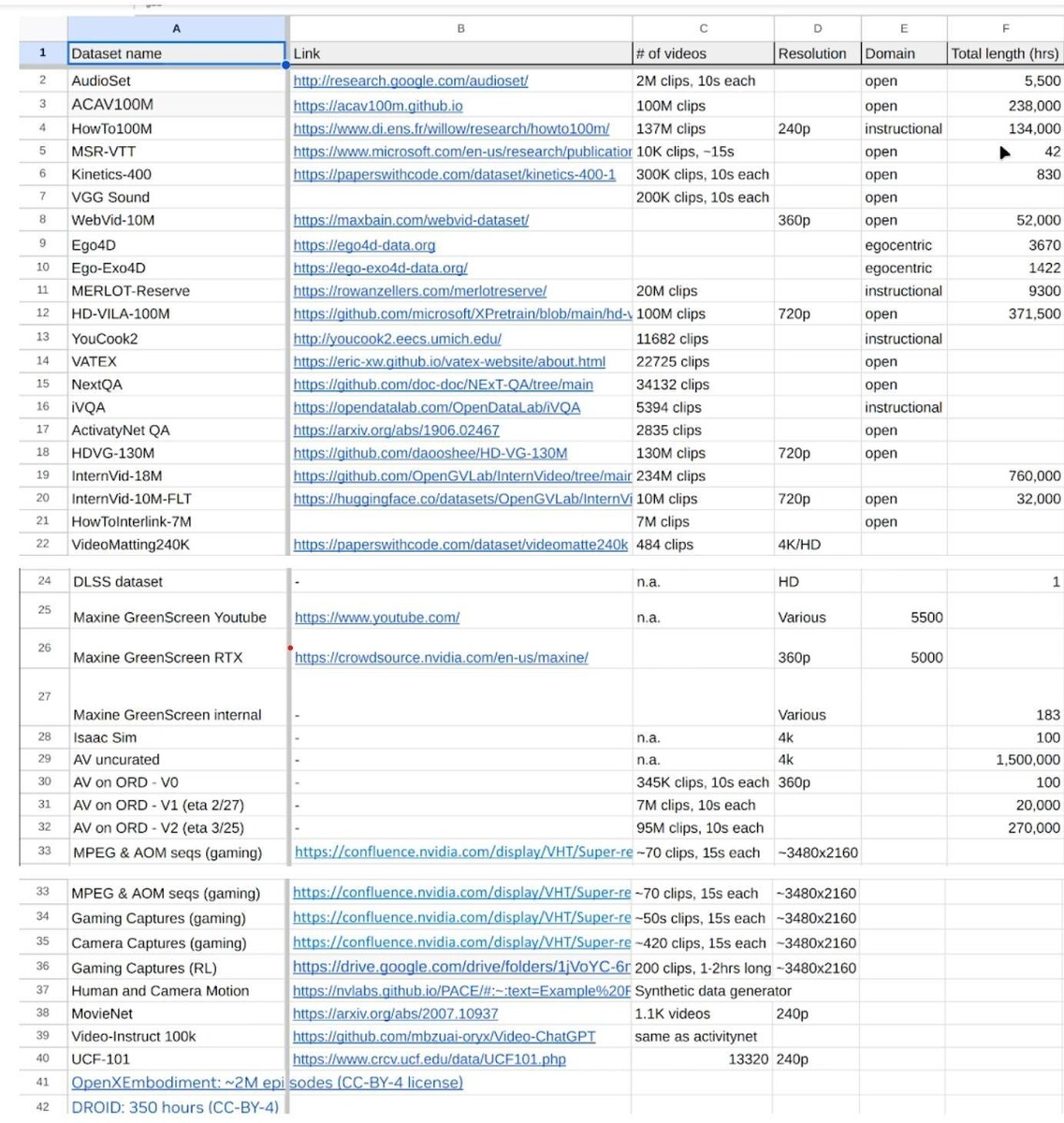
El uso de datos protegidos por derechos de autor para entrenar modelos de IA sigue siendo una zona gris desde el punto de vista legal. Conjuntos de datos públicos como InternVid-10M, HD-VG-130My otros basados en millones de vídeos de YouTube, pero sólo están pensados para la investigación académica y no para fines comerciales. Aunque Nvidia cuenta con investigadores académicos, el resultado acabará llegando a un producto comercial.
Ha habido pocas legislaciones en este sentido que ordenan normas de transparencia y exigen a las empresas que trabajan en modelos fundacionales de IA que colaboren con la FTC y la Oficina de Derechos de Autor. Pero las empresas no revelan necesariamente sus conjuntos de datos de origen, lo que dificulta mucho la auditoría.
A medida que las grandes empresas de IA siguen echando mano de todos los datos públicos disponibles para entrenar modelos más eficaces, los cambios legislativos son una necesidad imperiosa para garantizar la seguridad de los consumidores y proteger la propiedad intelectual de los creadores.
El año pasado, The New York Times demandó a OpenAI y Microsoft por el uso no autorizado de artículos protegidos por derechos de autor de la publicación para entrenar modelos de IA. En mayo, los artistas visuales presentaron una demanda contra Stability AI, Midjourney, DeviantArt y Runway AI por utilizar copias de sus obras para entrenar modelos de IA sin permiso.
YouTube se está convirtiendo en una mina de oro de datos para las empresas de IA. Recientemente, Wired informó que pesos pesados como Apple, Nvidia, Anthropic y Salesforce rasparon subtítulos de 173.536 vídeos de YouTube de más de 48.000 canales para entrenar su IA.
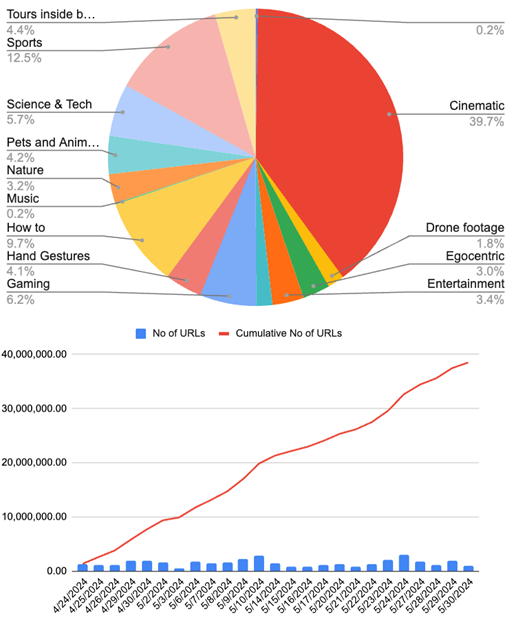
Hasta finales de mayo, el personal de Nvidia anunció internamente que había recopilado 38,5 millones de URL de vídeos, la mayoría de ellos de contenido cinematográfico. Los ingenieros también añadieron conjuntos de datos como Ego-Exo4D, Ego4D, HOI4Dy datos de juegos de GeForce Now.
Mientras que Ego-Exo4D y Ego4D pueden licenciarse tanto para uso académico como comercial, HOI4D se distribuye bajo una licencia CC BY-NC que prohíbe específicamente el uso comercial.
El equipo está entrenando actualmente un modelo 1B cada uno con 16 nodos, con planes de escalarlo a 10B.
Nvidia dijo a 404 Media por correo electrónico,"nuestros modelos y nuestros esfuerzos de investigación están en total conformidad con la letra y el espíritu de la ley de derechos de autor."
Mientras tanto, el director ejecutivo de Nvidia, Jensen Huang, parece estar contento con los progresos que está realizando su personal.
Al parecer, exclamó: "Gran actualización. Muchas empresas tienen que construir [modelos fundacionales] de vídeo FM. Nosotros podemos ofrecer un pipeline totalmente acelerado"
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Fuente(s)
404 Medios de comunicación (requiere registro)















