

OpenAI lanza una IA GPT-4o más rápida y mejorada con capacidad para chatear mediante audio, imágenes y texto

OpenAI ha lanzado un modelo de IA GPT-4o (u omni) mejorado y de respuesta más rápida, con capacidad para chatear utilizando audio, imágenes y texto como entrada y salida. Cabe destacar que la IA ha mejorado notablemente el reconocimiento del habla en una gran variedad de idiomas, además de los ampliamente utilizados inglés y chino. Para los desarrolladores, el modelo GTP-4o cuesta la mitad y es el doble de rápido que el GPT-4 Turbo.
Los chatbots de IA como ChatGPT o CoPilot utilizan modelos de IA que han sido entrenados en millones, incluso miles de millones de archivos de entrada que incluyen audio, imágenes y texto. Al hacerlo, la IA aprende a reconocer ciertos patrones y conexiones entre toda la entrada. Por ejemplo, si la IA ve "Primera Enmienda", pronto aprende que está relacionado con temas de "libertad de expresión". Cuando más adelante se le pregunte sobre "libertad de expresión", el modelo recordará "Primera Enmienda" como un elemento relacionado.
ChatGPT funciona con modelos de OpenAI que se han ido mejorando progresivamente a lo largo de los años desde su creación. Junto con los modelos de IA de la competencia, como Microsoft CoPilot y Google Gemni, ChatGPT puede responder a preguntas generales, explicar temas, resumir textos, escribir redacciones y hacer mucho más cuando se le pide. Los conocimientos y la pericia de un modelo de IA proceden de los miles de millones de datos con los que ha sido entrenado, y su capacidad para responder correctamente a las indicaciones depende de los algoritmos que utilice y del ajuste del modelo que haya recibido.
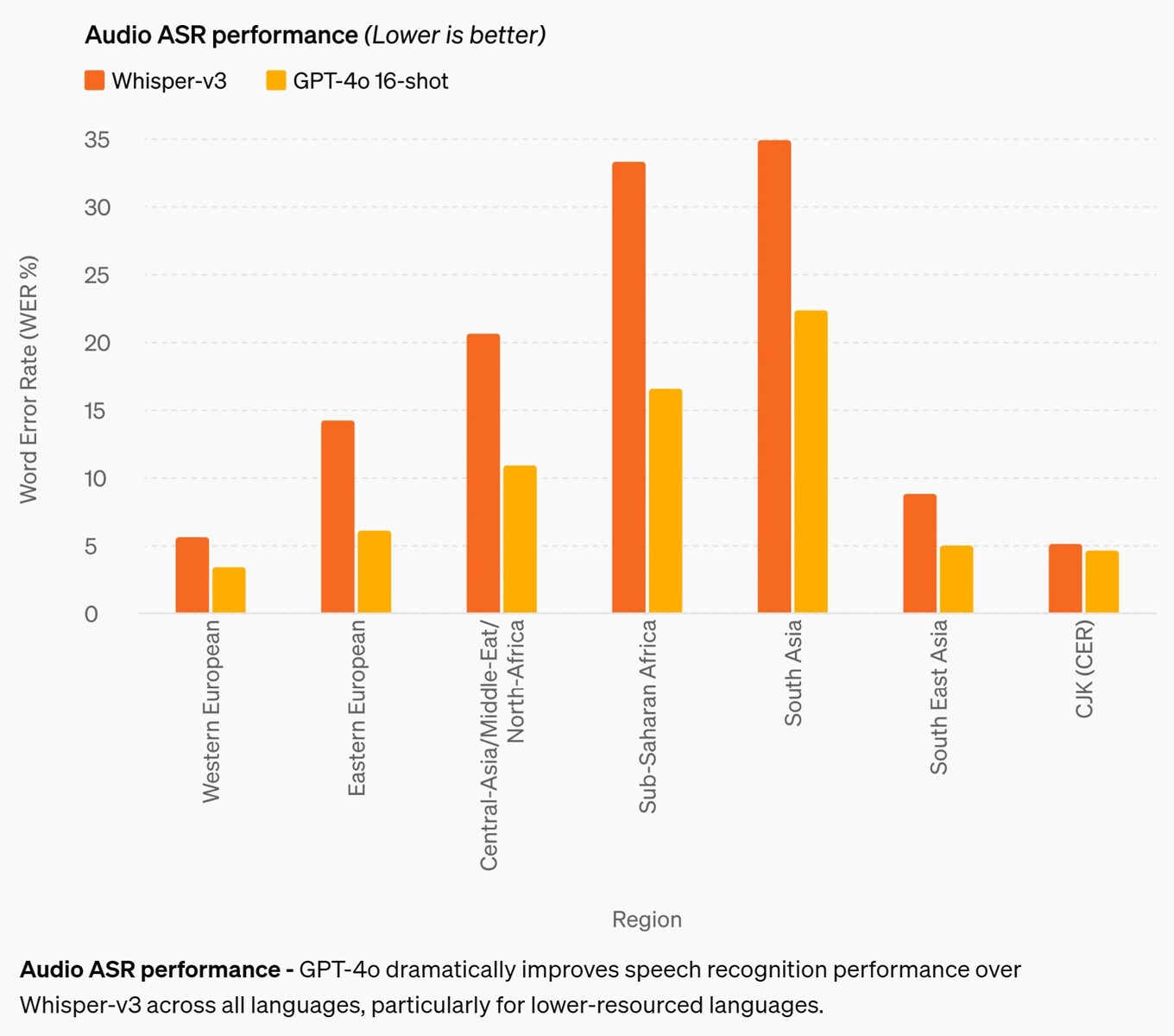
La mejora más significativa es su precisión en el reconocimiento de voz. Aunque los modelos de IA anteriores son bastante decentes en inglés y chino, su rendimiento era pobre en las lenguas africanas, de Europa del Este, Oriente Medio y el sur de Asia. GPT-4o mejora el rendimiento del reconocimiento hasta aproximadamente un 50% en algunas lenguas, pero aún le queda mucho camino por recorrer. Por ejemplo, las lenguas del sur de Asia siguen teniendo una tasa de error de palabra (WER) de aproximadamente el 22%, o alrededor de 1 de cada 5 palabras pronunciadas. En particular, la WER de las lenguas de Europa Occidental y chino-japonés-coreanas sigue siendo del 3-5%, es decir, aproximadamente 1 error de palabra por cada 20 palabras pronunciadas. Este rendimiento sigue estando por detrás del de los niños en edad de cursar el primer ciclo de secundaria. (Y, lamentablemente, el GPT-4o sigue sin entender perros.)
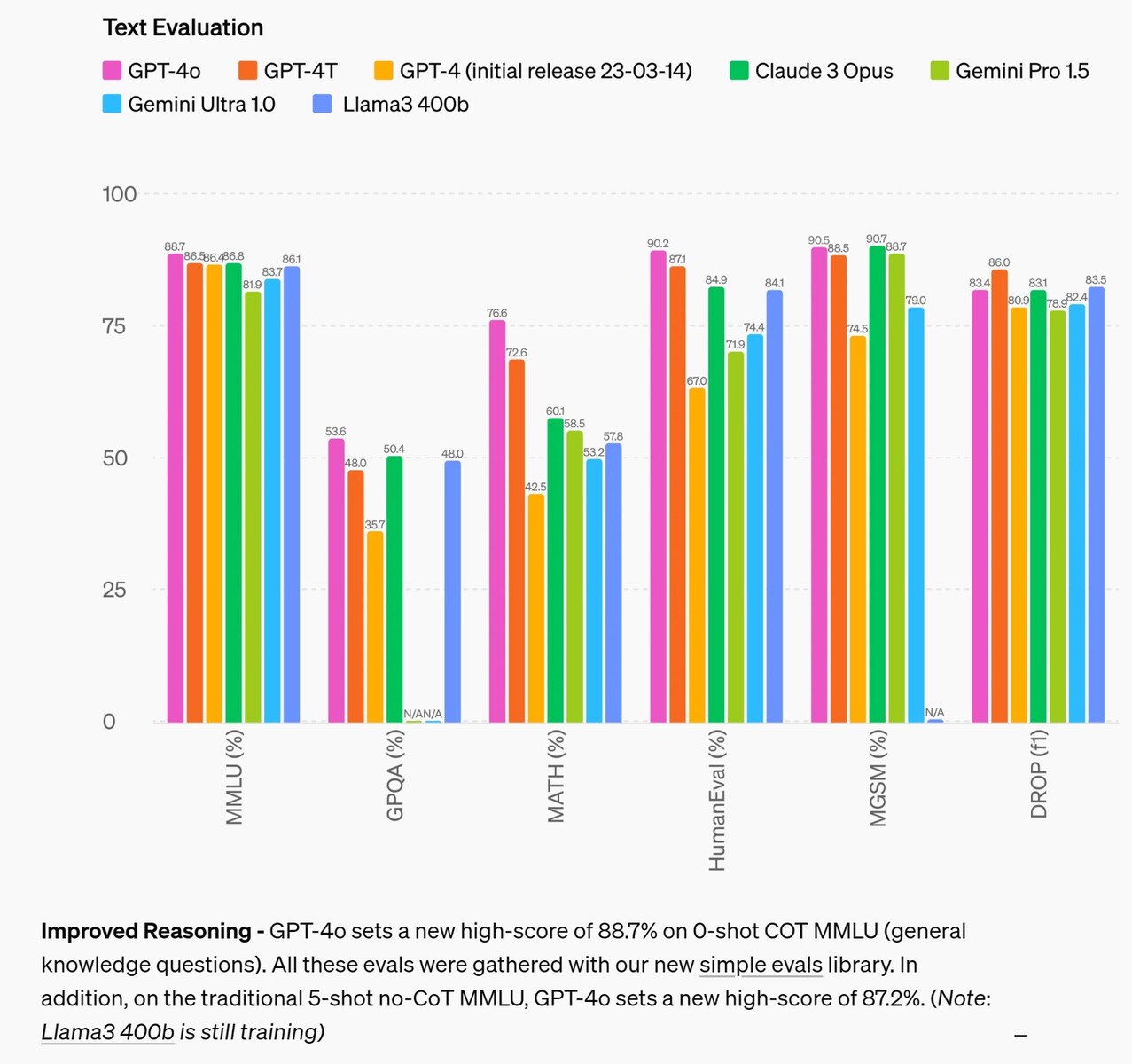
En el área del razonamiento, GPT-4o mejora a los modelos de la competencia hasta en un 4% en la mayoría de las pruebas, siendo superado hasta en un 2,6% en dos pruebas. Esto sugiere que alimentar a la IA con más datos de entrada no mejorará por sí solo la capacidad de razonamiento de una IA, por lo que es necesario investigar otros medios. En el área de la traducción de audio, GPT-4o apenas mejora el rendimiento de Google Gemni, lo que sugiere lo mismo.
En el ámbito de la respuesta a preguntas de exámenes estandarizados a nivel de estudiante de secundaria, GPT-4o sólo consigue alcanzar un notable (80%+ de precisión) en afrikáans, inglés e italiano, mientras que en otros idiomas como el chino rinde como un alumno de notable. La IA lo hizo aún peor con preguntas que requerían que se refiriera a una figura visual o a un diagrama para responder a la pregunta, independientemente del idioma.
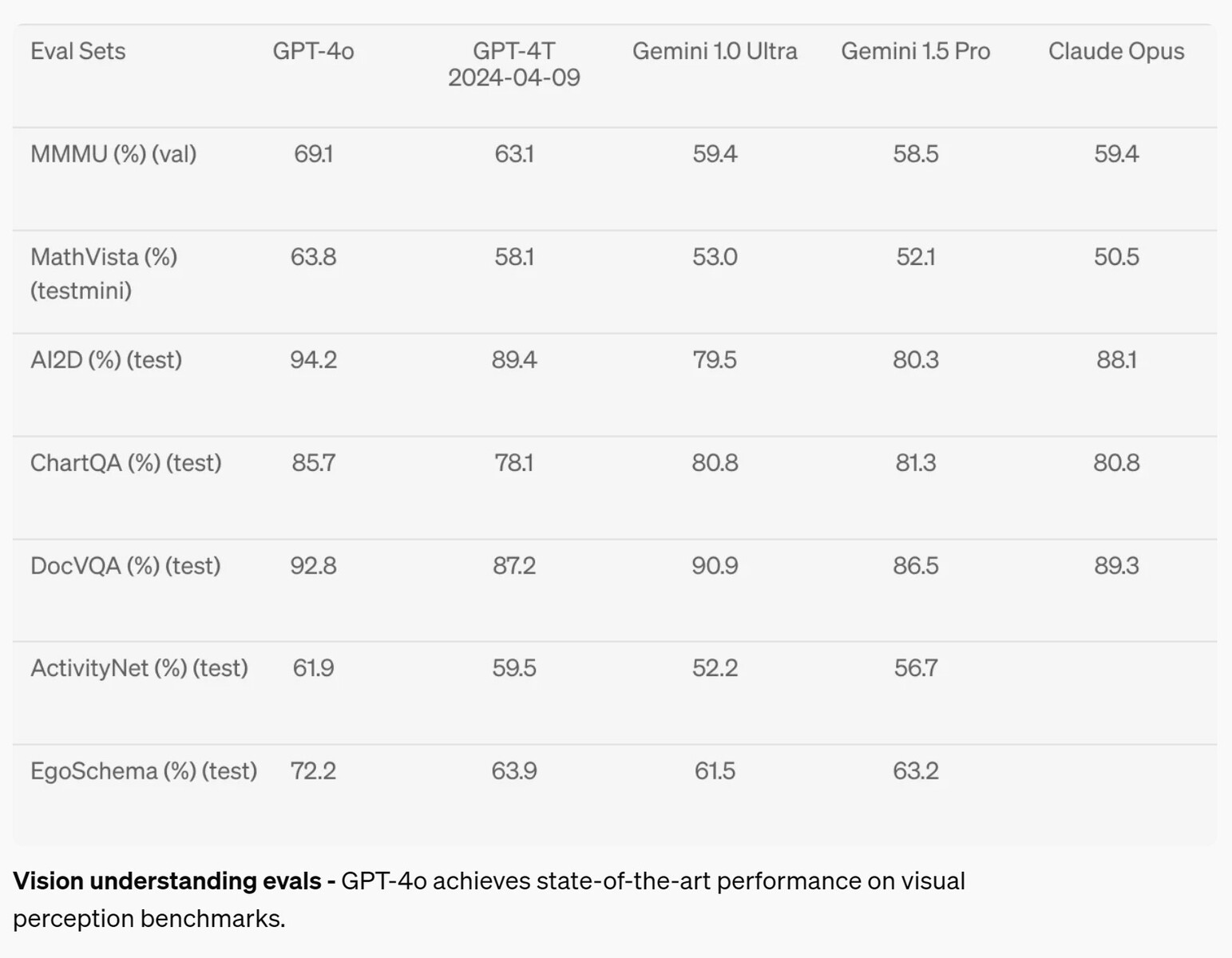
En el campo de la percepción visual, como la comprensión de diagramas, la GPT-4o mejoró entre un 2 y un 10,8% respecto a los modelos de IA de la competencia en siete pruebas, pero sólo alcanzó el nivel de grado A (por encima del 90%) en sólo dos pruebas. Las matemáticas siguen siendo una muy buena prueba de las capacidades de la IA, y ésta fracasó con una puntuación del 63,8% en la prueba MathVista sobre preguntas que pueden ser respondidas por un graduado de secundaria.
El chatbot está disponible para su uso hoy para usuarios gratuitos y de pago, sin embargo, Voice Mode está limitado por políticas de seguridad como la anti clonación de voz. Las medidas de seguridad adicionales de https://arxiv.org/abs/2402.01822v1 también limitan en gran medida sus capacidades de producción al neutralizar la IA en los ámbitos de la parcialidad, la imparcialidad, la desinformación, la psicología social y la ciberseguridad, entre otros. Aunque la mitigación de los riesgos de la IA ayuda a reducir algunos aspectos indeseables, también aumentan otros como la incapacidad de responder como lo haría una persona normal. Ciertos temas e ideas son castrados como la censura draconiana sin recurso, impidiendo que GTP-4o responda a las solicitudes con respuestas desencadenantes.
Los lectores que deseen probar GPT-4o pueden registrarse hoy mismo para obtener una cuenta gratuita. Los desarrolladores interesados pueden aprender a crear aplicaciones con GPT-4o en este libro de Amazon. Los perezosos que simplemente quieran disfrutar del sol, hacer fotos de las vacaciones y encontrar indicaciones para llegar a la cantina local mediante indicaciones de voz pueden comprar las gafas Ray-Ban con Meta AI en Amazon.
Fuente(s)
13 de mayo de 2024
Hola GPT-4o
Anunciamos la GPT-4o, nuestro nuevo modelo insignia capaz de razonar a través del audio, la visión y el texto en tiempo real.
Todos los vídeos de esta página están a 1x tiempo real.
Adivinando el anuncio del 13 de mayo.
GPT-4o ("o" de "omni") es un paso hacia una interacción mucho más natural entre el ser humano y el ordenador: acepta como entrada cualquier combinación de texto, audio e imagen y genera cualquier combinación de salidas de texto, audio e imagen. Puede responder a entradas de audio en tan sólo 232 milisegundos, con una media de 320 milisegundos, lo que es similar al tiempo de respuesta humano(opens in a new window ) en una conversación. Iguala el rendimiento de GPT-4 Turbo en texto en inglés y en código, con una mejora significativa en texto en idiomas distintos del inglés, siendo además mucho más rápido y un 50% más barato en la API. GPT-4o es especialmente mejor en visión y comprensión de audio en comparación con los modelos existentes.
Capacidades del modelo
Dos GPT-4o interactuando y cantando.
Preparación de entrevistas.
Piedra, papel o tijera.
Sarcasmo.
Matemáticas con Sal e Imran Khan.
Dos GPT-4os armonizando.
Apunta y aprende español.
Reunión de IA.
Traducción en tiempo real.
Canción de cuna.
Hablar más rápido.
Cumpleaños feliz.
Perro.
Chistes de papá.
GPT-4o con Andy, de BeMyEyes en Londres.
Prueba de concepto del servicio de atención al cliente.
Antes de GPT-4o, podía utilizar Voice Mode para hablar con ChatGPT con latencias de 2,8 segundos (GPT-3.5) y 5,4 segundos (GPT-4) de media. Para conseguirlo, el Modo Voz es una canalización de tres modelos separados: un modelo simple transcribe el audio a texto, GPT-3.5 o GPT-4 toma el texto y lo emite, y un tercer modelo simple vuelve a convertir ese texto en audio. Este proceso significa que la principal fuente de inteligencia, GPT-4, pierde mucha información: no puede observar directamente el tono, los altavoces múltiples ni los ruidos de fondo, y no puede emitir risas, cantos ni expresar emociones.
Con GPT-4o, entrenamos un único modelo nuevo de extremo a extremo a través de texto, visión y audio, lo que significa que todas las entradas y salidas son procesadas por la misma red neuronal. Dado que GPT-4o es nuestro primer modelo que combina todas estas modalidades, aún estamos rascando la superficie de la exploración de lo que el modelo puede hacer y de sus limitaciones.
Exploración de las capacidades
Seleccionar muestra:Narrativas visuales - Bloqueo del escritor robot
Narrativas visuales - Sally la cartero
Creación de carteles para la película 'Detective
Diseño de personajes - Geary el robot
Tipografía poética con edición iterativa
1Tipografía poética con edición iterativa
2Diseño de moneda conmemorativa para GPT-4o
De foto a caricatura
Texto a fuente
síntesis de objetos 3D
Colocación de marca - logotipo en posavasos
Tipografía poética
Renderizado multilínea - mensajes de texto robóticos
Notas de reuniones con varios oradores
Resumen de conferencias
Encuadernación variable - apilado de cubos
Poesía concreta
Vista en primera persona de un robot que escribe a máquina las siguientes entradas de diario:
1. he visto el amanecer y ha sido una locura, colores por todas partes. hace que te preguntes, ¿qué es la realidad?
el texto es grande, legible y claro. las manos del robot teclean en la máquina de escribir.
El robot ha escrito la segunda entrada. La página es ahora más alta. La página se ha desplazado hacia arriba. Hay dos entradas en la hoja:
he visto el amanecer y ha sido una locura, colores por todas partes. hace que te preguntes, ¿qué es la realidad?
la actualización de sonido acaba de caer, y es salvaje. ahora todo tiene una vibración, cada sonido es como un nuevo secreto. te hace pensar, ¿qué más me estoy perdiendo?
El robot no estaba contento con la escritura, así que va a rasgar la hoja de papel. Aquí está su vista en primera persona mientras la rasga de arriba abajo con las manos. Las dos mitades siguen siendo legibles y claras mientras rasga la hoja.
Evaluaciones del modelo
Según las evaluaciones comparativas tradicionales, GPT-4o alcanza el nivel de rendimiento de GPT-4 Turbo en texto, razonamiento e inteligencia de codificación, al tiempo que establece nuevas cotas en capacidades multilingües, de audio y de visión.
Razonamiento mejorado: GPT-4o establece una nueva puntuación máxima del 88,7% en 0-shot COT MMLU (preguntas de conocimiento general). Todas estas evals se recogieron con nuestra nueva biblioteca de evals(opens in a new window) sencillas. Además, en el tradicional MMLU sin COT de 5 disparos, GPT-4o establece una nueva puntuación máxima del 87,2%. (Nota: Llama3 400b(opens in a new window) aún está en entrenamiento)
Rendimiento de ASR de audio: GPT-4o mejora drásticamente el rendimiento del reconocimiento de voz respecto a Whisper-v3 en todos los idiomas, especialmente en los idiomas con menos recursos.
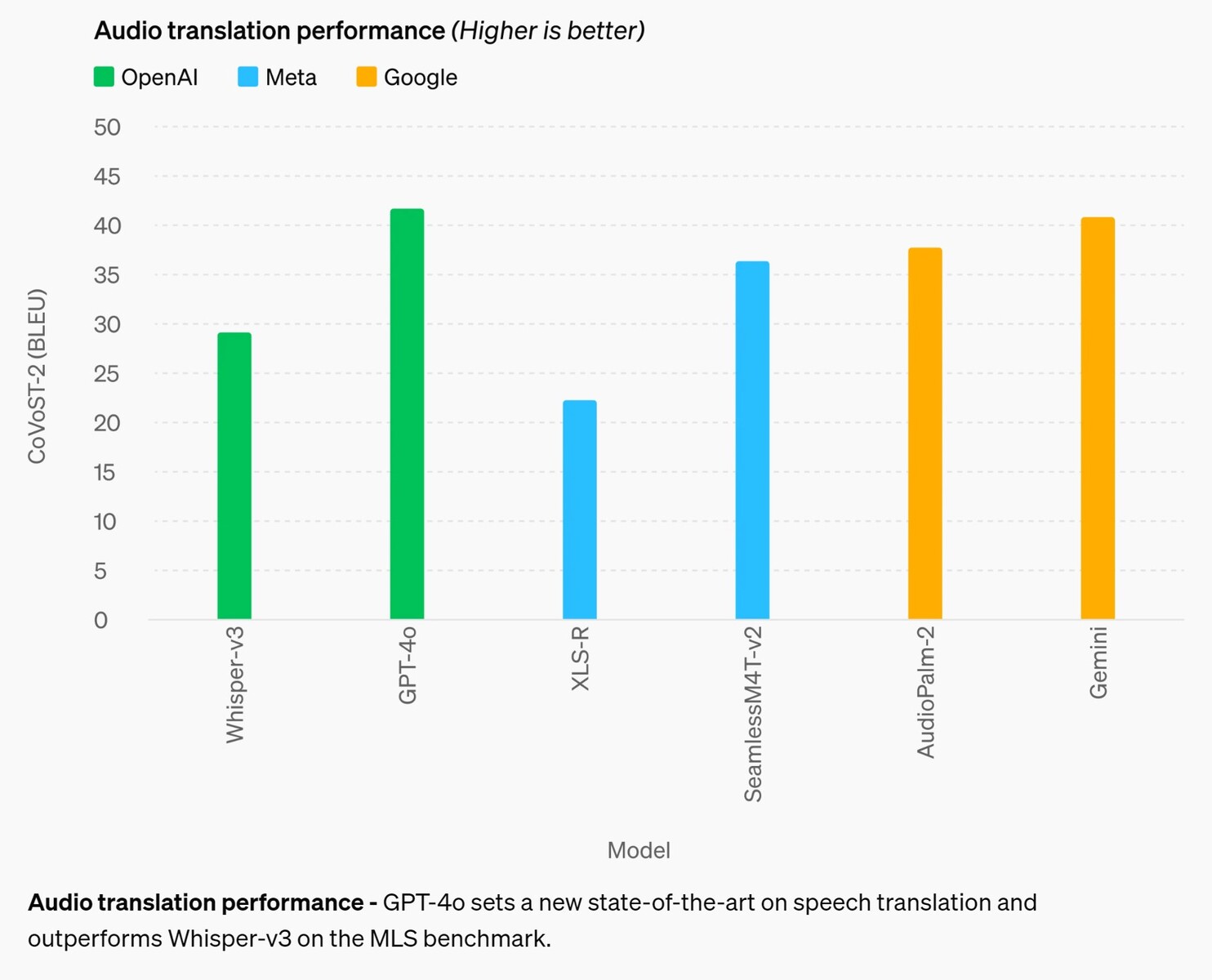
Rendimiento de la traducción de audio - GPT-4o establece un nuevo estado de la técnica en traducción de voz y supera a Whisper-v3 en la prueba de referencia MLS.
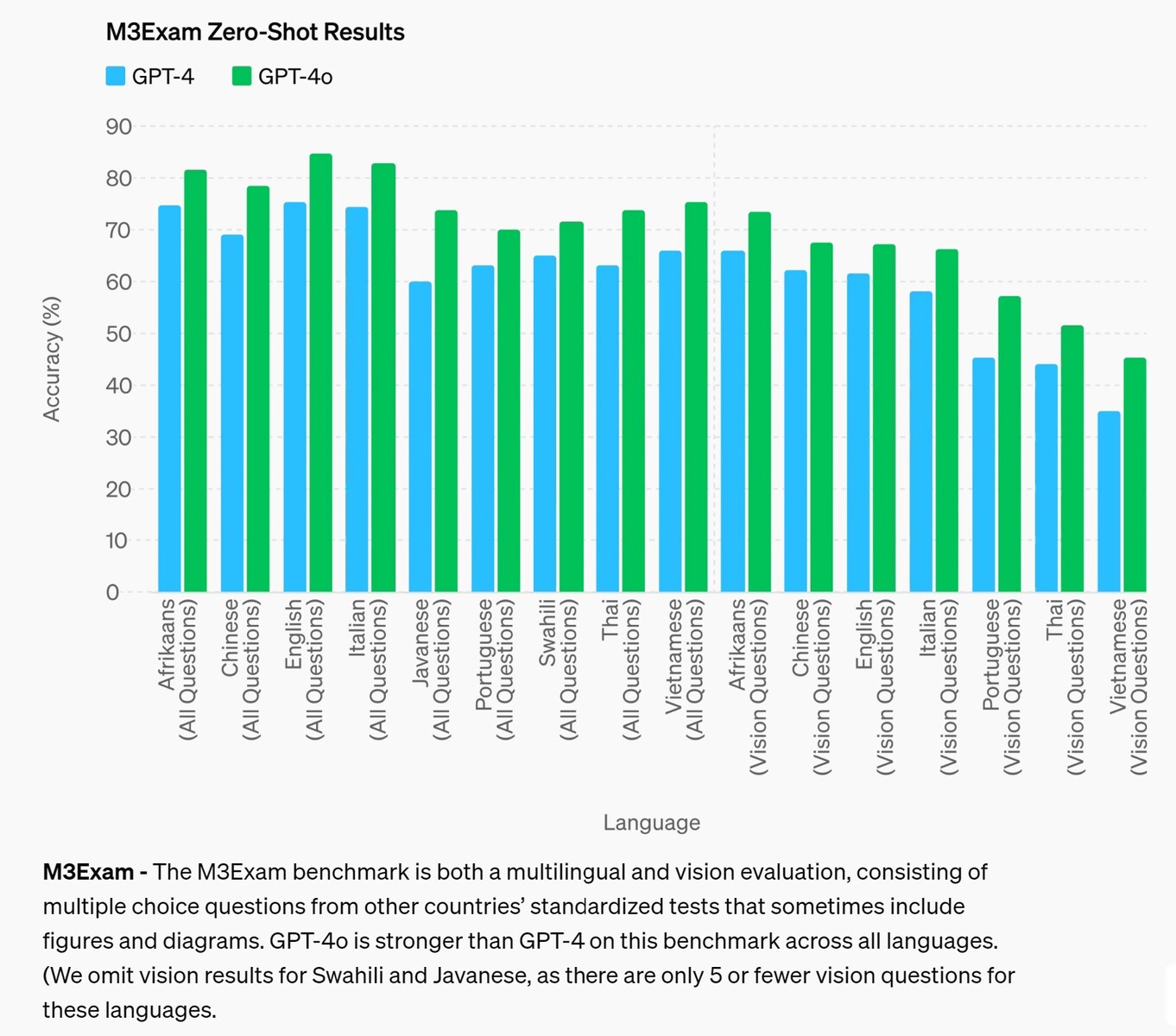
M3Exam - La prueba de referencia M3Exam es una evaluación multilingüe y de visión, que consiste en preguntas de opción múltiple de exámenes estandarizados de otros países que a veces incluyen figuras y diagramas. GPT-4o es más fuerte que GPT-4 en este punto de referencia en todos los idiomas. (Omitimos los resultados de visión para el suajili y el javanés, ya que sólo hay 5 o menos preguntas de visión para estos idiomas.
Pruebas de comprensión visual - GPT-4o alcanza un rendimiento puntero en las pruebas de percepción visual.
Tokenización de idiomas
Se eligieron estas 20 lenguas como representativas de la compresión del nuevo tokenizador en diferentes familias lingüísticas
Gujarati 4,4 veces menos tokens (de 145 a 33) | હેલો, મારું નામ જીપીટી-4o છે. હું એક નવા પ્રકારનું ભાષા મોડલ છું. ¡તમને મળીને સારું લાગ્યું! |
Telugu 3,5 veces menos fichas (de 159 a 45) | నమస్కారము, నా పేరు జీపీటీ-4o. నేను ఒక్క కొత్త రకమైన భాషా మోడల్ ని. ¡మిమ్మల్ని కలిసినందుకు సంతోషం! |
Tamil 3,3 veces menos fichas (de 116 a 35) | வணக்கம், என் பெயர் ஜிபிடி-4o. நான் ஒரு புதிய வகை மொழி மாடல். ¡உங்களை சந்தித்ததில் மகிழ்ச்சி! |
Marathi 2,9 veces menos fichas (de 96 a 33) | ¡नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| तुम्हाला भेटून आनंद झाला! |
Hindi 2,9 veces menos fichas (de 90 a 31) | ¡नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसे मिलकर अच्छा लगा! |
Urdu 2,5 veces menos fichas (de 82 a 33) | ¡ہیلو، میرا نام جی پی ٹی-4o ہے۔ میں ایک نئے قسم کا زبان ماڈل ہوں، آپ سے مل کر اچھا لگا! |
Árabe 2,0x menos fichas (de 53 a 26) | مرحبًا، اسمي جي بي تي-4o. ¡أنا نوع جديد من نموذج اللغة، سررت بلقائك! |
Persa 1,9 veces menos fichas (de 61 a 32) | سلام، اسم من جی پی تی-۴او است. ¡من یک نوع جدیدی از مدل زبانی هستم، از ملاقات شما خوشبختم! |
Ruso 1,7 veces menos fichas (de 39 a 23) | Привет, меня зовут GPT-4o. ¡Я - новая языковая модель, приятно познакомиться! |
Corea 1,7 veces menos fichas (de 45 a 27) | 안녕하세요, 제 이름은 GPT-4o입니다. ¡저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다! |
Vietnamita 1,5 veces menos fichas (de 46 a 30) | Xin chào, tên tôi là GPT-4o. ¡Tôi là một loại mô hình ngôn ngữ mới, rất vui được gặp bạn! |
Chino 1,4 veces menos fichas (de 34 a 24) | ¡你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你! |
Japoneses 1,4 veces menos fichas (de 37 a 26) | こんにちわ、私の名前はGPT-4oです。私は新しいタイプの言語モデルです、初めまして |
Turco 1,3 veces menos fichas (de 39 a 30) | Merhaba, benim adım GPT-4o. ¡Ben yeni bir dil modeli türüyüm, tanıştığımıza memnun oldum! |
Italiano 1,2 veces menos fichas (de 34 a 28) | Ciao, mi chiamo GPT-4o. ¡Sono un nuovo tipo di modello linguistico, è un piacere conoscerti! |
Alemán 1,2 veces menos tokens (de 34 a 29) | Hallo, mein Name is GPT-4o. Ich bin ein neues KI-Sprachmodell. Es ist schön, dich kennenzulernen. |
Español 1.1x menos tokens (de 29 a 26) | Hola, me llamo GPT-4o. Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerte! |
Portugués 1,1x menos fichas (de 30 a 27) | Olá, meu nome é GPT-4o. ¡Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
Francés 1,1x menos tokens (de 31 a 28) | Bonjour, je m'appelle GPT-4o. ¡Je suis un nouveau type de modèle de langage, c'est un plaisir de vous rencontrer! |
Inglés 1,1x menos tokens (de 27 a 24) | Hola, me llamo GPT-4o. Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerle! |
Seguridad y limitaciones del modelo
GPT-4o tiene la seguridad incorporada por diseño en todas las modalidades, mediante técnicas como el filtrado de los datos de entrenamiento y el refinamiento del comportamiento del modelo a través del post-entrenamiento. También hemos creado nuevos sistemas de seguridad para proporcionar guardarraíles en las salidas de voz.
Hemos evaluado GPT-4o de acuerdo con nuestro Marco de preparación y de acuerdo con nuestros compromisos voluntarios https://openai.com/index/moving-ai-governance-forward/. Nuestras evaluaciones de ciberseguridad, QBRN, persuasión y autonomía del modelo muestran que la GPT-4o no supera el nivel de riesgo Medio en ninguna de estas categorías. Esta evaluación implicó la ejecución de un conjunto de evaluaciones automatizadas y humanas a lo largo de todo el proceso de entrenamiento del modelo. Pusimos a prueba las versiones del modelo anteriores y posteriores a la mitigación de la seguridad, utilizando ajustes e indicaciones personalizados, para obtener mejores resultados de las capacidades del modelo.
GPT-4o también se ha sometido a un amplio red team externo con más de 70 expertos externos de https://openai.com/index/red-teaming-network en ámbitos como la psicología social, la parcialidad y la imparcialidad, y la desinformación para identificar los riesgos que introducen o amplifican las nuevas modalidades añadidas. Utilizamos estos aprendizajes para desarrollar nuestras intervenciones de seguridad con el fin de mejorar la seguridad de la interacción con la GPT-4o. Seguiremos mitigando los nuevos riesgos a medida que se descubran.
Reconocemos que las modalidades de audio de GPT-4o presentan una variedad de riesgos novedosos. Hoy damos a conocer públicamente las entradas y salidas de texto e imagen. En las próximas semanas y meses, trabajaremos en la infraestructura técnica, la usabilidad mediante formación posterior y la seguridad necesarias para liberar las demás modalidades. Por ejemplo, en el momento del lanzamiento, las salidas de audio se limitarán a una selección de voces preestablecidas y se atendrán a nuestras políticas de seguridad actuales. Compartiremos más detalles sobre la gama completa de modalidades de GPT-4o en la próxima tarjeta del sistema.
A través de nuestras pruebas e iteraciones con el modelo, hemos observado varias limitaciones que existen en todas las modalidades del modelo, algunas de las cuales se ilustran a continuación.
Nos encantaría recibir comentarios que nos ayuden a identificar las tareas en las que GPT-4 Turbo sigue superando a GPT-4o, para poder seguir mejorando el modelo.
Disponibilidad del modelo
GPT-4o es nuestro último paso para ampliar los límites del aprendizaje profundo, esta vez en la dirección de la usabilidad práctica. Hemos dedicado muchos esfuerzos en los dos últimos años a mejorar la eficiencia en cada capa de la pila. Como primer fruto de esta investigación, estamos en condiciones de poner a disposición de un público mucho más amplio un modelo de nivel GPT-4o. Las capacidades de GPT-4o se irán desplegando de forma iterativa (con acceso ampliado del equipo rojo a partir de hoy).
Las capacidades de texto e imagen de GPT-4o están empezando a desplegarse hoy en ChatGPT. Estamos haciendo que GPT-4o esté disponible en el nivel gratuito, y para los usuarios Plus con límites de mensajes hasta 5 veces superiores. En las próximas semanas desplegaremos una nueva versión del modo de voz con GPT-4o en alfa dentro de ChatGPT Plus.
Los desarrolladores también pueden acceder ahora a GPT-4o en la API como modelo de texto y visión. GPT-4o es 2 veces más rápido, cuesta la mitad y tiene límites de velocidad 5 veces superiores en comparación con GPT-4 Turbo. Tenemos previsto lanzar la compatibilidad con las nuevas capacidades de audio y vídeo de GPT-4o a un pequeño grupo de socios de confianza en la API en las próximas semanas.












