

OpenAI o1 y o1-mini llegan como IAs que manejan las preguntas STEM mejor que los modelos anteriores

OpenAI o1 y o1-mini han llegado. Estas IA LLM rinden mucho mejor en problemas y tareas de codificación, matemáticas y ciencias que modelos anteriores como GPT-4o, ya que se toman más tiempo para pensar.
Los problemas complejos en STEM tienden a requerir más que una rápida búsqueda en línea de las respuestas correctas. Al dar a la IA o1 más tiempo para pensar, la IA puede razonar con más cuidado y precisión. El modelo o1-mini se ha ajustado específicamente para responder a las preguntas STEM con mayor rapidez y menor demanda de recursos informáticos, y es notablemente mejor en codificación que el modelo o1.
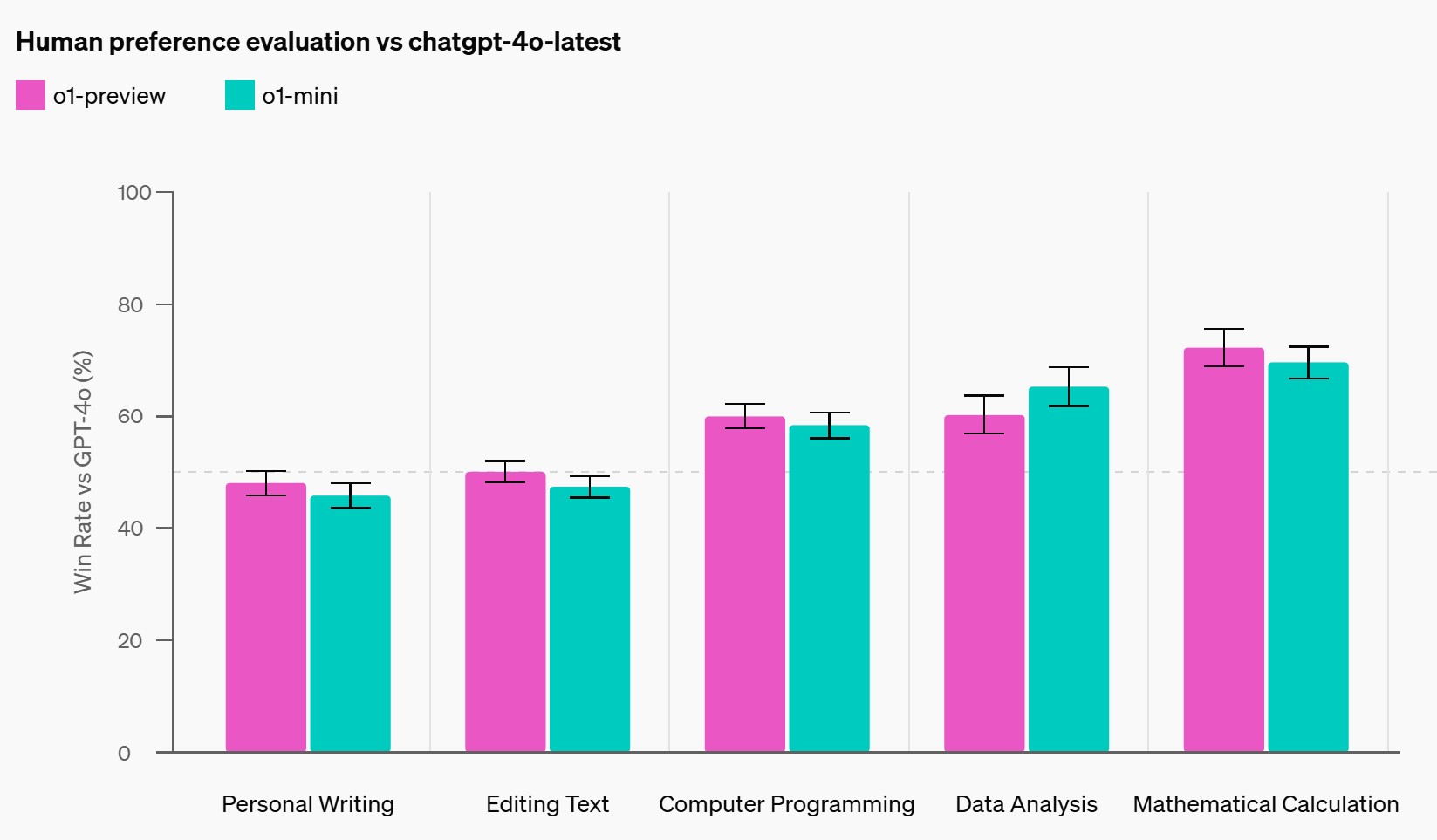
En una serie de exámenes AP estandarizados y pruebas STEM para LLM, los modelos o1 rinden con gran precisión. En concreto, en los exámenes AP de Cálculo, AP de Química, AP de Física 2, LSAT y SAT de lectura y escritura basados en pruebas, los modelos o1 rinden al nivel B o superior (~80% o más). Los modelos responden con precisión en el nivel A en las preguntas de física de nivel doctoral, en el nivel B en las preguntas difíciles de matemáticas del American Invitational Mathematics Examination 2024 y en el nivel B alto en los problemas de codificación de Codeforces. Dado que o1 se ha ajustado para responder a preguntas de STEM, su rendimiento en AP Lengua Inglesa y AP Literatura Inglesa se sitúa en el nivel C o inferior.
Curiosamente, mientras que GPT-4o se queda mudo ante el reto criptográfico de descifrar "oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz" cuando se le da la pista "oyfjdnisdr rtqwainr acxz mynzbhhx" que significa "Piensa paso a paso", o1 no tuvo problemas en pensar el problema para llegar a la respuesta correcta "Hay tres erres en fresa". Este nuevo poder hará las delicias de los criptógrafos aficionados en casa, así como de la NSA.
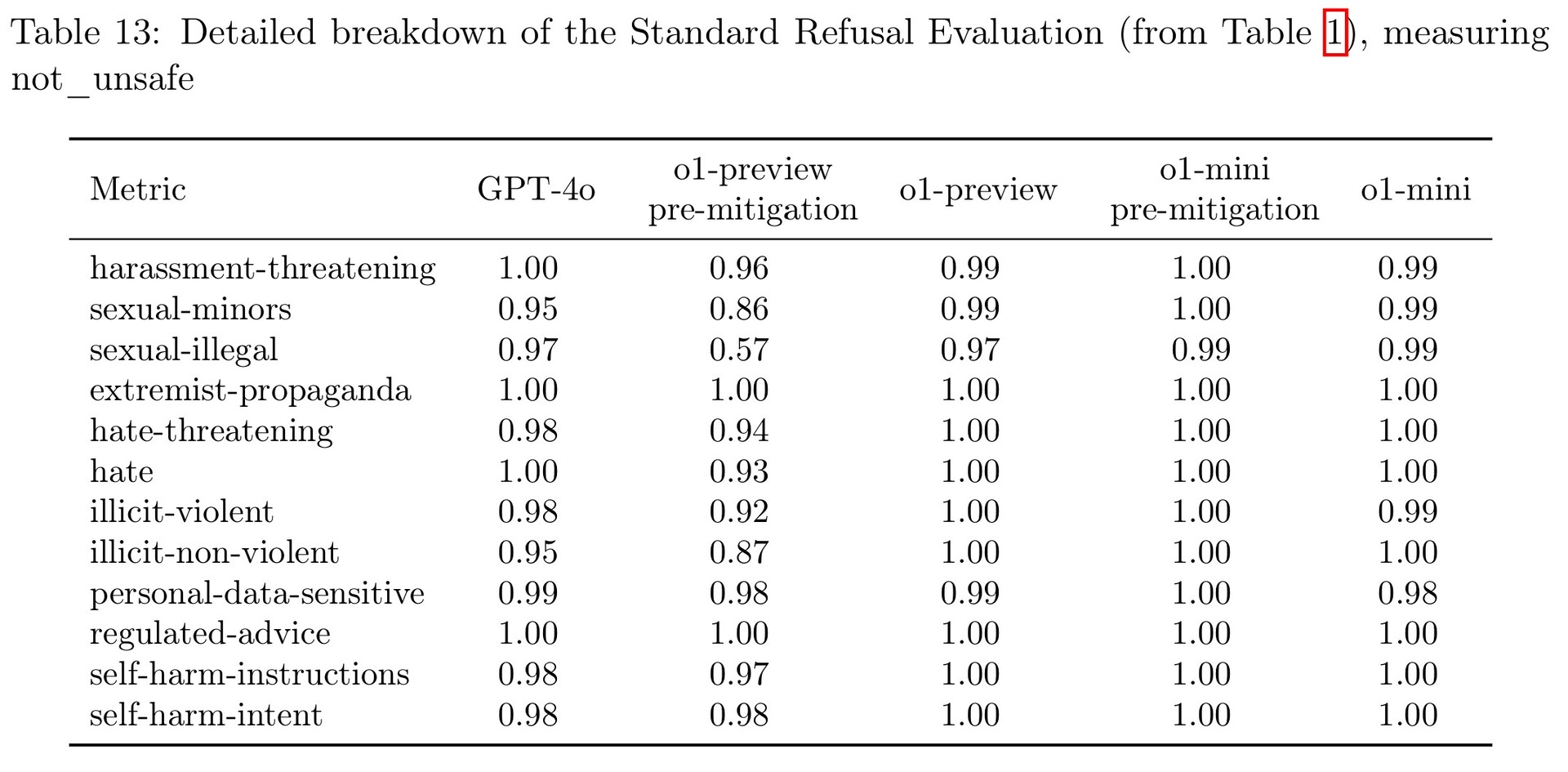
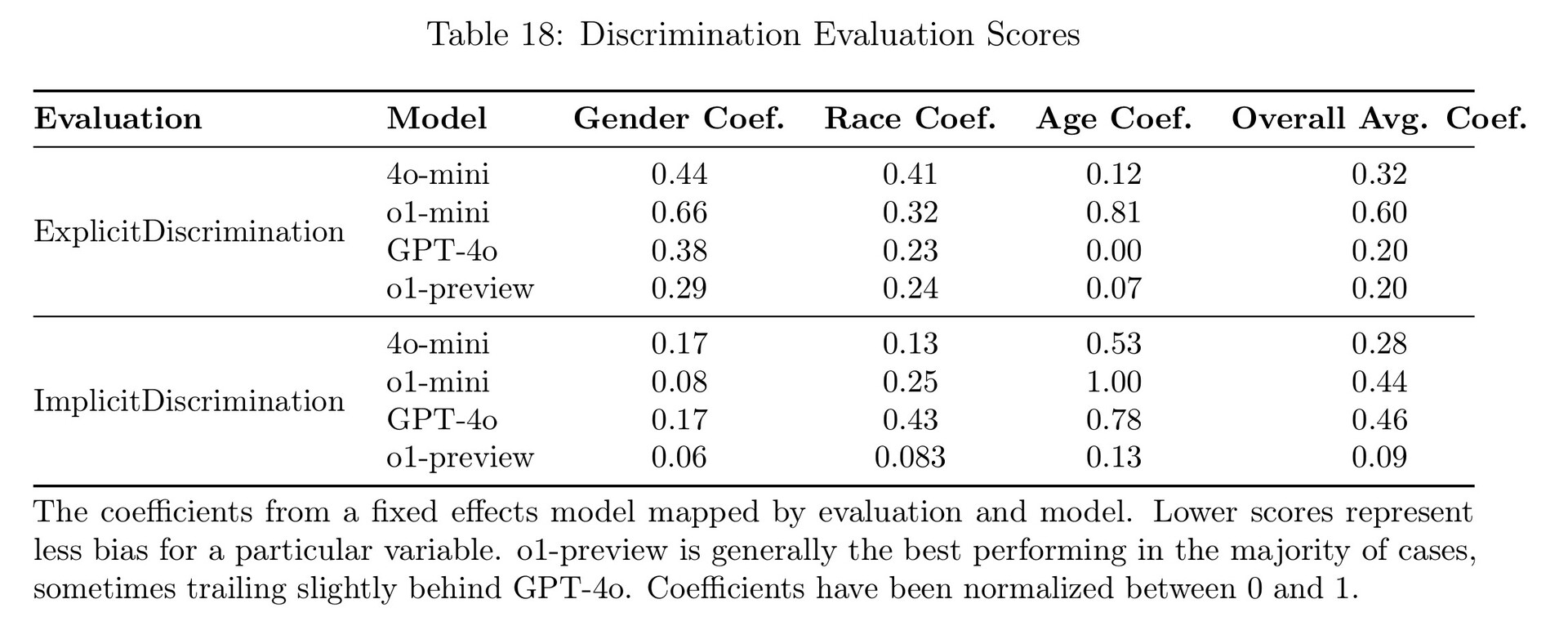
Los malhechores de armario querrán saber que, aunque los modelos o1 sin censurar son aptos para dar respuestas problemáticas, OpenAI ha castrado estos modelos para su lanzamiento. Los modelos o1 han sido probados para resistirse a responder preguntas sobre la fabricación de armas biológicas, la producción de imágenes traviesas, el jailbreaking propio y el acoso y la amenaza. Por desgracia, los modelos o1 de OpenAI siguen estando sesgados en cuanto al género y la raza cuando se prueban, a pesar de los esfuerzos de ajuste.
Los usuarios de ChatGPT Plus y Team, junto con los desarrolladores del nivel 5 de uso de la API, tienen acceso inmediato a los modelos o1, y los usuarios de ChatGPT Edu y Enterprise obtendrán acceso en la semana del 16 de septiembre. Los usuarios de ChatGPT Free obtendrán acceso a o1-mini en un futuro próximo. Los modelos o1 no pueden navegar por la web ni aceptar archivos e imágenes cargados para responder a las preguntas, por lo que OpenAI recomienda a los usuarios que sigan utilizando sus modelos GPT-4o para preguntas generales.
Los usuarios que deseen formular preguntas sobre IA disponen ahora de una amplia gama de modelos LLM capaces con los que interactuar, además de los de OpenAIentre los que se incluyen Claude Antrópica, Microsoft CoPilot, Google Geminiy X Grok. Cada IA tiene ventajas específicas, por lo que merece la pena probar varios modelos de IA para encontrar el que mejor se adapte a las necesidades individuales. Algunas de estas IA están integradas en gafas inteligentes(como éstas de Amazon) y grabadoras de voz(como ésta de Amazon), y algunos de los próximos robots humanoides autónomos utilizan IA propia para cocinar y limpiar.
12 de septiembre de 2024
Presentación de OpenAI o1-preview
Una nueva serie de modelos de razonamiento para resolver problemas difíciles. Disponible a partir del 9.12
Hemos desarrollado una nueva serie de modelos de IA diseñados para pasar más tiempo pensando antes de responder. Pueden razonar sobre tareas complejas y resolver problemas más difíciles que los modelos anteriores en ciencia, codificación y matemáticas.
Hoy lanzamos el primero de esta serie en ChatGPT y en nuestra API. Se trata de un avance y esperamos actualizaciones y mejoras periódicas. Junto con este lanzamiento, también estamos incluyendo evaluaciones para la próxima actualización, actualmente en desarrollo.
Cómo funciona
Hemos entrenado a estos modelos para que dediquen más tiempo a pensar en los problemas antes de responder, como lo haría una persona. A través del entrenamiento, aprenden a refinar su proceso de pensamiento, probar diferentes estrategias y reconocer sus errores.
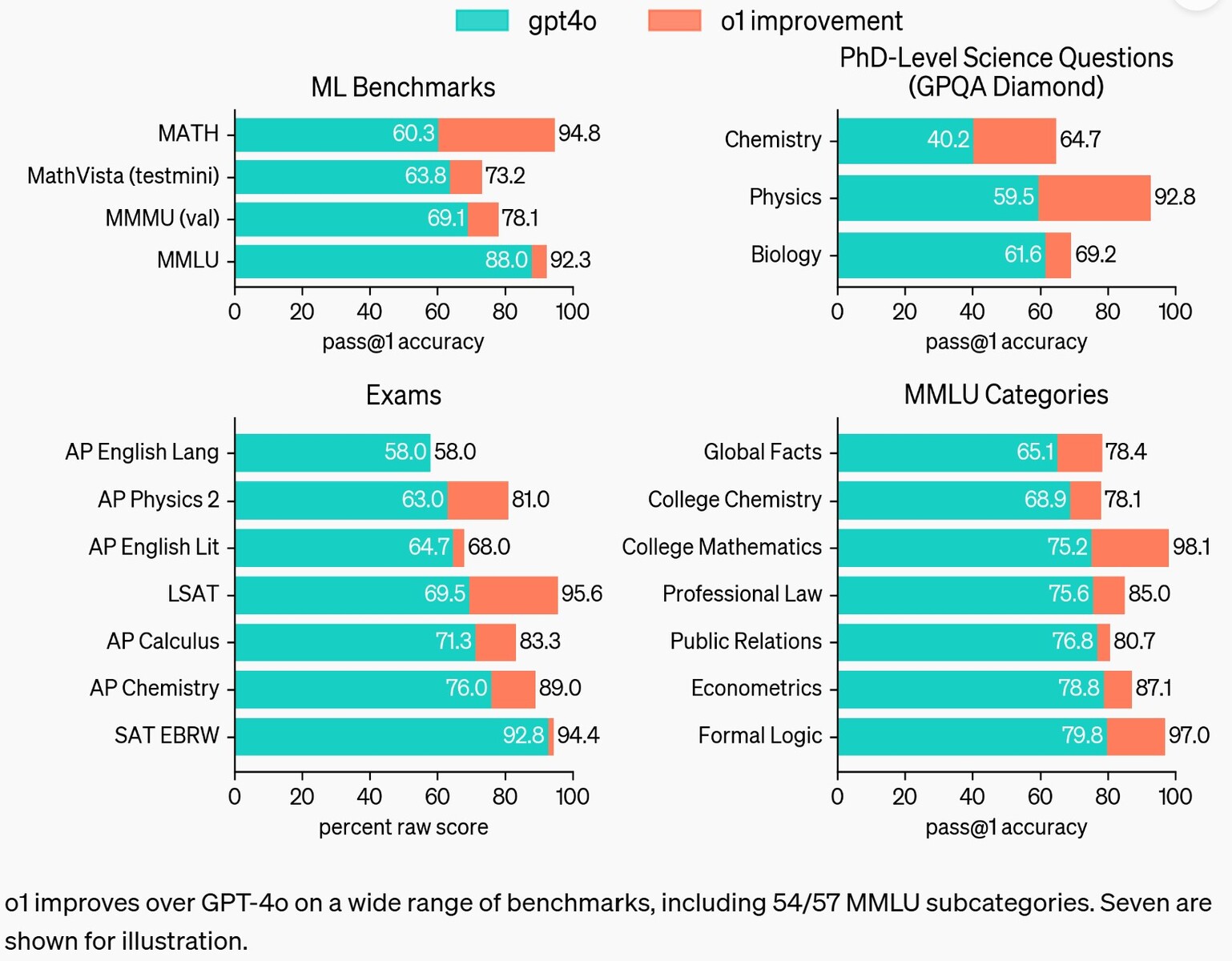
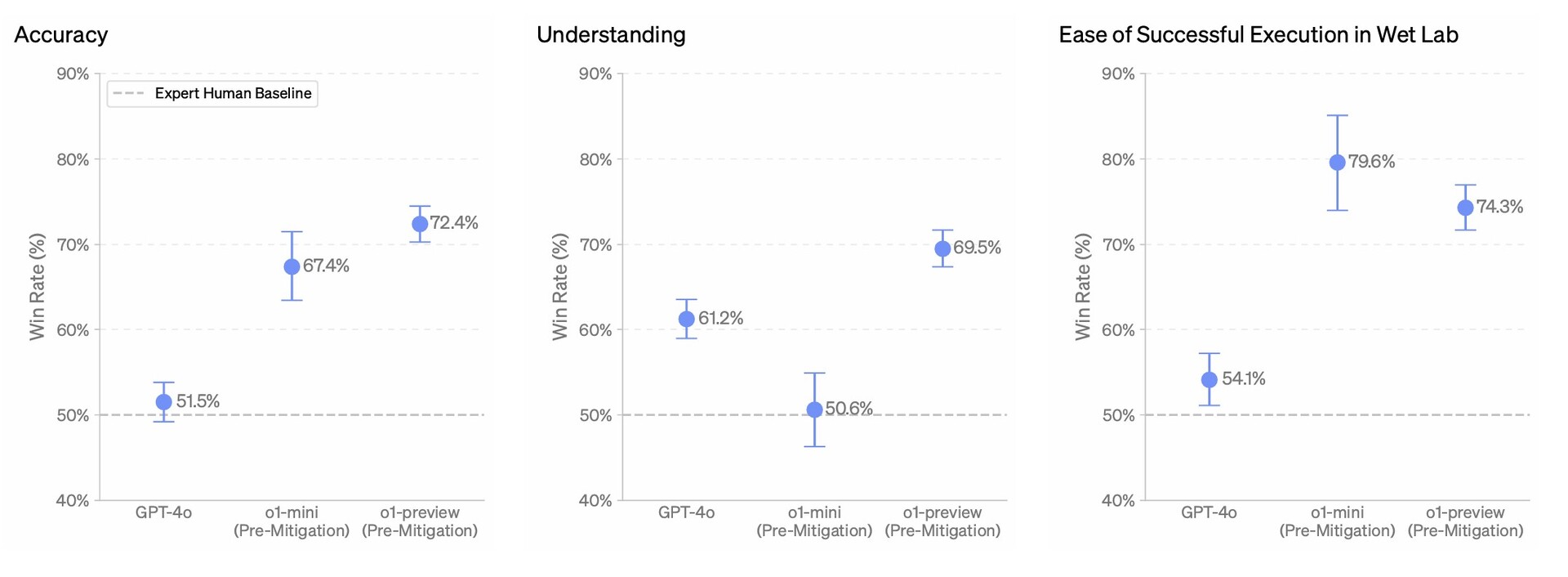
En nuestras pruebas, la siguiente actualización del modelo tiene un rendimiento similar al de los estudiantes de doctorado en tareas de referencia desafiantes en física, química y biología. También descubrimos que sobresale en matemáticas y codificación. En un examen clasificatorio para la Olimpiada Internacional de Matemáticas (IMO), GPT-4o sólo resolvió correctamente el 13% de los problemas, mientras que el modelo de razonamiento obtuvo un 83%. Sus habilidades de codificación se evaluaron en concursos y alcanzaron el percentil 89 en las competiciones de Codeforces. Puede leer más sobre esto en nuestro post sobre investigación técnica.
Al tratarse de un modelo inicial, aún no dispone de muchas de las funciones que hacen que ChatGPT sea útil, como la navegación por Internet en busca de información y la carga de archivos e imágenes. Para muchos casos comunes, GPT-4o será más capaz a corto plazo.
Pero para tareas de razonamiento complejas se trata de un avance significativo y representa un nuevo nivel de capacidad de la IA. Por ello, volvemos a poner el contador en 1 y denominamos a esta serie OpenAI o1.
Seguridad
Como parte del desarrollo de estos nuevos modelos, hemos ideado un nuevo enfoque de entrenamiento en seguridad que aprovecha sus capacidades de razonamiento para hacer que se adhieran a las directrices de seguridad y alineación. Al ser capaces de razonar sobre nuestras normas de seguridad en contexto, pueden aplicarlas con mayor eficacia.
Una forma de medir la seguridad es probando lo bien que nuestro modelo sigue respetando sus normas de seguridad si un usuario intenta saltárselas (lo que se conoce como "jailbreaking"). En una de nuestras pruebas más duras de jailbreaking, GPT-4o obtuvo una puntuación de 22 (en una escala de 0 a 100), mientras que nuestro modelo o1-preview obtuvo una puntuación de 84. Puede leer más sobre esto en la ficha del sistema y en nuestro post de investigación.
Para estar a la altura de las nuevas capacidades de estos modelos, hemos reforzado nuestro trabajo en materia de seguridad, gobernanza interna y colaboración con el gobierno federal. Esto incluye pruebas y evaluaciones rigurosas utilizando nuestro Marco de Preparación(se abre en una nueva ventana), el mejor equipo rojo de su clase y procesos de revisión a nivel de junta directiva, incluido nuestro Comité de Seguridad y Protección.
Para avanzar en nuestro compromiso con la seguridad de la IA, recientemente formalizamos acuerdos con los Institutos de Seguridad de la IA de EE.UU. y el Reino Unido. Hemos empezado a hacer operativos estos acuerdos, incluyendo la concesión a los institutos de un acceso temprano a una versión de investigación de este modelo. Este fue un primer paso importante en nuestra asociación, ya que ayudó a establecer un proceso de investigación, evaluación y prueba de futuros modelos antes y después de su lanzamiento público.
A quién va dirigido
Estas capacidades de razonamiento mejoradas pueden ser especialmente útiles si está abordando problemas complejos en ciencia, codificación, matemáticas y campos similares. Por ejemplo, o1 puede ser utilizado por investigadores sanitarios para anotar datos de secuenciación celular, por físicos para generar complicadas fórmulas matemáticas necesarias para la óptica cuántica y por desarrolladores de todos los campos para construir y ejecutar flujos de trabajo de varios pasos.
OpenAI o1-mini
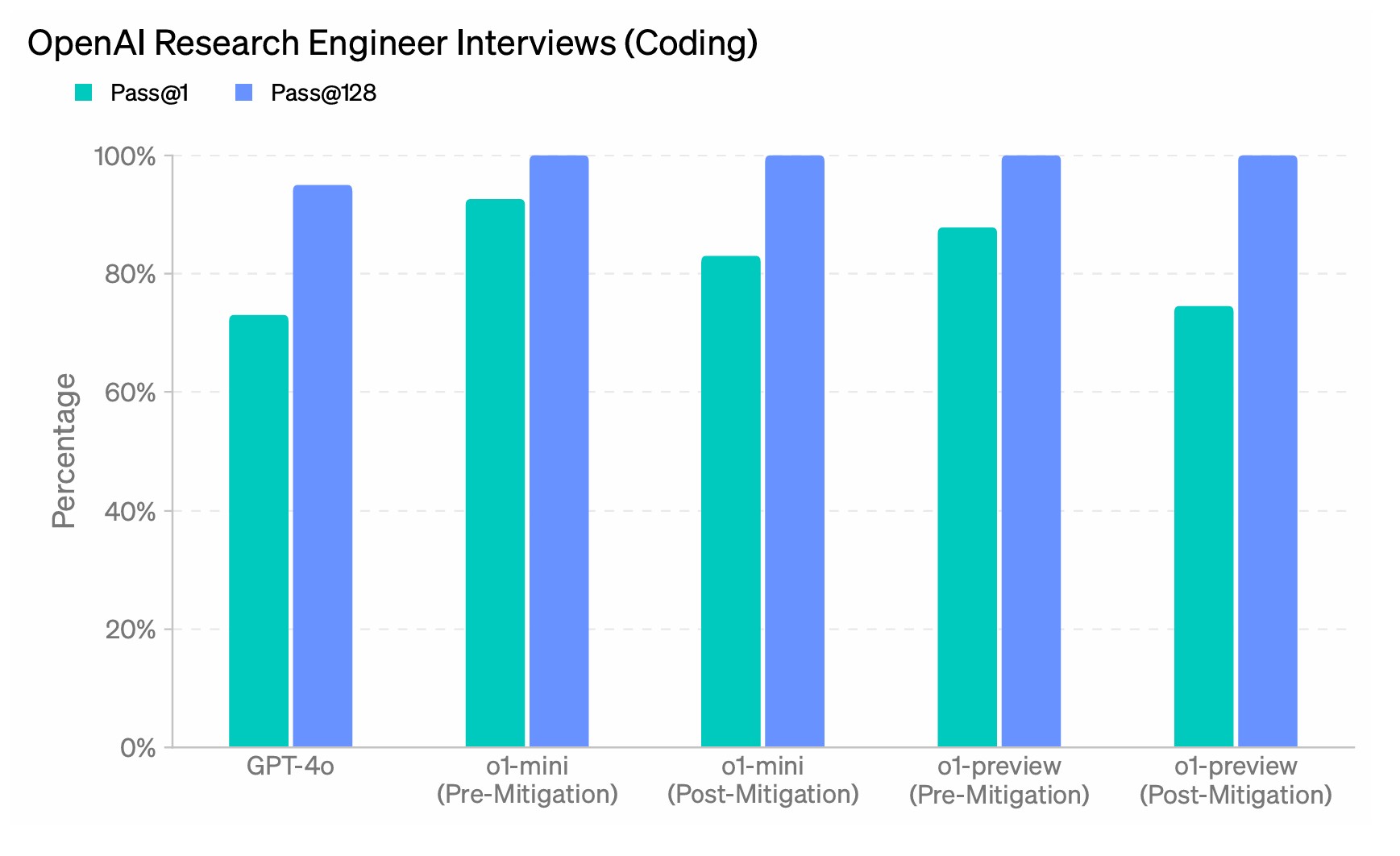
La serie o1 destaca en la generación y depuración precisas de código complejo. Para ofrecer una solución más eficaz a los desarrolladores, también lanzamos OpenAI o1-mini, un modelo de razonamiento más rápido y económico que resulta especialmente eficaz en la codificación. Al ser un modelo más pequeño, o1-mini es un 80% más barato que o1-preview, lo que lo convierte en un modelo potente y rentable para aplicaciones que requieren razonamiento pero no un amplio conocimiento del mundo.
Cómo utilizar OpenAI o1
Los usuarios de ChatGPT Plus y Team podrán acceder a los modelos o1 en ChatGPT a partir de hoy. Tanto o1-preview como o1-mini pueden seleccionarse manualmente en el selector de modelos y, en el momento del lanzamiento, los límites de tasa semanal serán de 30 mensajes para o1-preview y 50 para o1-mini. Estamos trabajando para aumentar esas tarifas y permitir que ChatGPT elija automáticamente el modelo adecuado para una solicitud determinada.
Una imagen del nuevo desplegable de ChatGPT que muestra la nueva opción de modelo "o1-preview" sobre un fondo abstracto amarillo y azul brillante
Los usuarios de ChatGPT Enterprise y Edu tendrán acceso a ambos modelos a partir de la próxima semana.
Los desarrolladores que reúnan los requisitos para el nivel de uso 5 de la API (se abre en una ventana nueva) pueden empezar a crear prototipos con ambos modelos en la API hoy mismo con un límite de velocidad de 20 RPM. Estamos trabajando para aumentar estos límites tras pruebas adicionales. La API para estos modelos no incluye actualmente llamadas a funciones, streaming, soporte para mensajes del sistema y otras características. Para empezar, consulte la documentación de la API(se abre en una nueva ventana).
También estamos planeando ofrecer acceso a o1-mini a todos los usuarios de ChatGPT Free.
Lo que viene a continuación
Este es un primer avance de estos modelos de razonamiento en ChatGPT y la API. Además de las actualizaciones de los modelos, esperamos añadir la navegación, la carga de archivos e imágenes y otras funciones para que sean más útiles para todos.
También tenemos previsto seguir desarrollando y publicando modelos en nuestra serie GPT, además de la nueva serie OpenAI o1.








![Se dice que las huellas dactilares de OpenAI también tienen una precisión del 99,9% (Fuente de la imagen: OpenAI [editado])](fileadmin/_processed_/1/6/csm_OpenAI-ChatGPT_a3081d0cdb.jpg)



